国産生成AIはChatGPTを超えるか?日本語特化モデルの可能性と産業応用への期待

はじめに:生成AIの波と日本独自の課題
2023年のChatGPTの登場以来、生成AIは私たちの仕事や生活に急速に浸透し、その可能性は日々拡大しています。OpenAIのChatGPT、GoogleのGemini、AnthropicのClaudeといった海外製の汎用AIは、テキスト生成、情報収集、プログラミング支援など、多岐にわたるタスクでその能力を発揮しています。これらのAIは、インターネット上の膨大な多言語データを学習しており、日本語での応答も非常に自然になってきています。
しかし、グローバルな汎用AIが進化する一方で、日本国内では「日本語の微妙なニュアンスや文化をより深く理解できるAIが欲しい」「企業の機密情報や個人情報を安全に扱いたい」「日本の法規制や商習慣に対応したAIが必要だ」といった、日本独自のニーズが高まっています。こうした背景から、近年、日本国内の企業や研究機関が開発する「国産生成AI」や、特に日本語の処理に強みを持つ「日本語特化モデル」が注目を集めています。
果たして、これらの日本語特化・国産生成AIは、世界のトップを走るChatGPTのような汎用AIを超えることができるのでしょうか?そして、日本の産業やビジネスにどのような変革をもたらす可能性があるのでしょうか?本記事では、日本語特化・国産生成AIが注目される理由から、主要なモデルの紹介、汎用AIとの比較、そして産業応用への期待と課題まで、詳しく解説していきます。
なぜ今、日本語特化・国産生成AIが注目されるのか?
日本語特化・国産生成AIへの関心が高まっているのには、いくつかの明確な理由があります。
1. 日本語の特性への対応
日本語は、漢字、ひらがな、カタカナが混在し、主語が省略されることが多く、文脈に大きく依存する言語です。また、敬語や謙譲語といった複雑な表現、曖昧な言い回しも多用されます。海外製の汎用AIも日本語に対応していますが、学習データの大部分が英語であるため、これらの日本語特有の複雑さやニュアンスを完全に捉えきれない場合があります。日本語に特化して学習されたモデルは、より自然で正確な日本語の文章生成や、文脈を深く理解した応答が可能になります。
2. 日本独自の文化・商習慣の理解
ビジネス文書の形式、会議の進め方、顧客対応における丁寧さなど、日本には独自の文化や商習慣が存在します。これらの背景知識を学習した国産AIは、日本のビジネスシーンに即した、より適切なアウトプットを生成できます。例えば、日本の法律や規制に関する質問、特定の業界慣習に基づいた問い合わせなどに対し、より正確で信頼性の高い情報を提供できる可能性があります。
3. データ主権・セキュリティの確保
企業が生成AIを導入する際に最も懸念される点の一つが、データの取り扱いです。特に機密情報や個人情報を含むデータを海外のAIサービスに入力することには、情報漏洩やプライバシー侵害のリスクが伴います。国内で開発・運用される国産AIであれば、日本の法規制(個人情報保護法など)に準拠しやすく、データが国内のデータセンターで管理されるため、セキュリティやデータ主権の観点から安心感があります。多くの企業向け国産AIプラットフォームは、入力データがAIの学習に利用されないことを保証しています。
4. 産業競争力の強化
AI技術は、今後の産業競争力を左右する重要な要素です。基盤となるLLMの開発能力を国内で持つことは、特定の産業分野に特化したAIの開発や、既存システムとの連携を容易にし、日本の産業全体のDXを加速させることにつながります。また、国内での開発・運用は、新たな雇用創出や技術者の育成にも貢献します。
これらの理由から、日本語の高度な処理能力、国内での安心安全な運用、そして日本の産業への貢献といった点で、日本語特化・国産生成AIへの期待が高まっています。
主要な日本語特化・国産生成AIモデルの紹介
日本国内でも、様々な企業や研究機関が日本語に強みを持つLLMや、それを活用したプラットフォームの開発を進めています。ここでは、その一部をご紹介します。
基盤モデルの開発
- NTT「tsuzumi」: 軽量でありながら高い日本語処理能力を持つことが特徴です。パラメータサイズが比較的小さく、GPUやCPUでの推論動作が可能で、特定の業界や企業組織に特化したチューニングが容易です。
- NEC「cotomi」: 130億パラメータを持ち、世界最大級の日本語特化モデルとされています。コンパクトで超軽量化されており、標準的なサーバーでも動作可能な設計を目指しています。
- 富士通「Takane」: 世界トップレベルの日本語性能を持つ企業向けLLMとして開発されています。Nutanixなどのプライベートクラウド環境での提供も進められており、機密性の高いデータを扱う業務での活用が期待されています。
- サイバーエージェント「CyberAgentLM」: 日本語能力を評価するベンチマークで高い性能を記録しているモデルです。AWSなどのクラウドサービス上での利用も可能になっています。
- ELYZA(KDDI子会社): 東京大学松尾研究室発のスタートアップが開発。Meta社のLlamaシリーズなどをベースに日本語学習を重ねており、軽量モデルから大規模モデルまで開発しています。日本語ベンチマークでGPT-3.5やGemini 1.0 Proに匹敵する性能を達成しています。
- 楽天「Rakuten AI」: Mistral AI社のモデルをベースに、日本語・英語データを学習させて開発。オープンソースとして提供されており、日本語テキスト生成タスクで高い性能を発揮します。
- Lightblue「ao-Karasu」: 720億パラメータを持つ日本語特化LLMで、日本語ベンチマークで国内最高水準の評価を得ています。チャットツール連携など、実用的な応用も進められています。
- rinna「Youri」: Meta社のLlama 2をベースに、日本語学習を強化したモデル。日本語の学習量が少ないLlamaの弱点を補い、高水準のベンチマークスコアを記録しています。
これらのモデルは、それぞれ異なるアプローチで日本語の理解・生成能力を高めており、今後の進化が期待されます。
企業向け国産SaaSプラットフォーム
基盤モデルを直接利用するだけでなく、セキュリティや既存システム連携、日本語でのサポートなどを強化した企業向けプラットフォームも登場しています。
- JAPAN AI(ジーニー): 複数のLLM(ChatGPT, Gemini, Claudeなど)に対応し、独自開発の高性能RAG技術で社内外データからの高精度な情報検索・応答を実現。上場企業水準のセキュリティと手厚いサポートが特徴です。
- exaBase生成AI(エクサウィザーズ): GPT-4など複数のLLMと企業独自データを組み合わせるRAG技術に強み。国内データセンター運用、詳細なセキュリティ管理、リアルタイム効果測定機能などを提供します。
- HEROZ ASK(HEROZ株式会社): ChatGPTなどのLLMを活用し、社内データ(PDF, テキスト, 音声など)の検索・要約・翻訳、音声データの文字起こしなどをサポート。建設、製造、ITなど幅広い業界での導入実績があります。
これらのプラットフォームは、日本語での利用に最適化されているだけでなく、企業が生成AIを安全かつ効果的に導入・運用するための機能を提供しています。
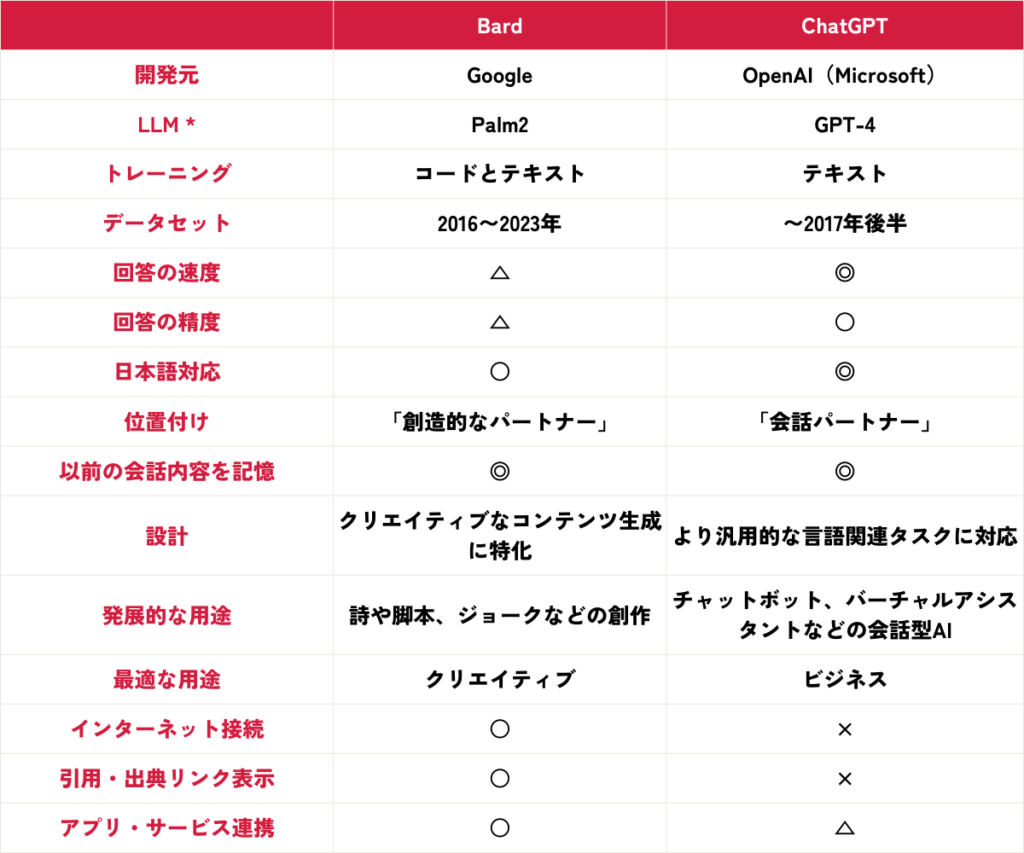
汎用AI(ChatGPT, Gemini, Claudeなど)と日本語特化・国産AIの比較
海外製の汎用AIと日本語特化・国産AIは、それぞれ異なる強みを持っています。どちらが優れているかではなく、用途や目的に応じて使い分けることが重要です。
日本語の自然さ・精度
- 汎用AI: 近年のモデル(GPT-4o, Gemini 2.5, Claude 3.7など)は日本語の自然さが大幅に向上しており、日常会話や一般的な文章作成においては非常に高品質な出力を提供します。しかし、日本語特有の言い回しや、特定の分野の専門用語、あるいは微妙なニュアンスを含む長文などでは、不自然さが見られることもあります。
- 日本語特化・国産AI: 日本語データを集中的に学習しているため、より自然で人間らしい日本語の文章生成や、日本語特有の文脈理解に強みを持つモデルがあります。特に、日本の文化や商習慣に根ざした表現、あるいは特定の業界の専門用語を含む文書の処理において、その精度が期待されます。
長文処理能力
- 汎用AI: Gemini 2.5 Pro (2Mトークン), Claude 3.7 (200Kトークン), ChatGPT (128Kトークン) など、非常に長いコンテキスト長を持つモデルが登場しており、数百ページ規模の文書処理が可能です。日本語の長文も処理できますが、日本語特有の構造や表現が複雑な場合、理解や要約の精度に影響が出る可能性があります。
- 日本語特化・国産AI: 日本語の長文構造や文脈依存性を考慮して設計されているモデルは、日本語のレポートや議事録、契約書といった長文の読解、要約、分析において、より高い精度を発揮する可能性があります。特に、日本語の専門文書や社内文書の処理に強みを持つモデルが開発されています。
最新情報への対応
- 汎用AI: GeminiやMicrosoft CopilotはGoogle検索やBingと連携しており、常に最新の情報にアクセスできます。ChatGPTやClaudeもWebブラウジング機能を持ち、最新情報を取得可能です。汎用的な最新情報の収集には非常に強力です。
- 日本語特化・国産AI: 基盤モデルによってはWeb検索機能を持ちませんが、企業向けプラットフォームではRAG技術を活用し、社内データや特定の外部データソースと連携することで、最新かつ関連性の高い情報を取得できます。日本の特定のニュースやトレンド、法改正情報など、日本に特化した最新情報への対応が期待されます。
セキュリティ・データ管理
- 汎用AI: ChatGPT Enterprise, Gemini for Google Workspace, Claude for Enterprise, Microsoft 365 Copilotといった企業向けプランでは、セキュリティやデータ保護が強化されています。しかし、海外のサービスであるため、データの保管場所や法規制への準拠について、国内企業が懸念を持つ場合があります。
- 日本語特化・国産AI: 国内のデータセンターで運用され、日本の法規制に準拠した設計がされているため、機密情報や個人情報の取り扱いにおいて安心感があります。多くの国産プラットフォームは、入力データがAIの学習に利用されないことを明確に保証しています。
コスト・料金体系
- 汎用AI: 無料プランも提供されていますが、高性能モデルや高度な機能を利用するには有料プラン(月額20ドル程度)が必要です。API利用は従量課金が一般的です。
- 日本語特化・国産AI: モデルやプラットフォームによって料金体系は異なります。企業向けSaaS型サービスが多く、月額料金や利用量に応じた課金となります。初期導入コストや運用コストを含めて、費用対効果を検討する必要があります。
汎用AIの強みと日本語特化AIの強み
- 汎用AIの強み: 多機能性、幅広い知識ベース、マルチモーダル対応の進化、大規模なユーザーコミュニティと豊富なプラグイン/拡張機能エコシステム。
- 日本語特化・国産AIの強み: 高度な日本語理解・生成能力、日本独自の文化・商習慣への対応、国内での安心安全なデータ管理、特定の産業分野への特化可能性。
結論として、汎用AIは幅広い用途に対応できる万能性、日本語特化・国産AIは日本語や日本独自の文脈における精度とセキュリティに強みがあると言えます。どちらが「超える」というより、それぞれの得意分野を活かした使い分けや連携が、今後のAI活用の鍵となるでしょう。
産業応用への期待と具体的な活用事例
日本語特化・国産生成AIは、日本の様々な産業やビジネスシーンで大きな変革をもたらす可能性を秘めています。以下に具体的な活用事例を挙げます。
1. ビジネス文書作成・要約
契約書、議事録、報告書、メールなど、日本語で書かれた大量のビジネス文書の作成や要約を効率化できます。日本語の長文処理に強い国産AIは、複雑な日本語の文書構造や専門用語を正確に理解し、高品質な要約やドラフトを生成できます。これにより、文書作成にかかる時間を大幅に削減し、従業員はより創造的・戦略的な業務に集中できます。
2. 社内ナレッジマネジメント
社内に蓄積されたマニュアル、FAQ、過去の議事録、技術資料などの非構造化データを、RAG(検索拡張生成)技術と組み合わせることで、高精度な社内AIアシスタントを構築できます。日本語特化AIは、これらの日本語文書の内容を深く理解し、従業員からの質問に対して、関連性の高い情報を迅速かつ正確に提供します。これにより、情報検索にかかる時間を削減し、組織全体の知識共有と活用を促進します。
3. 顧客対応の高度化
日本語の自然な対話に強い国産AIを活用することで、より人間らしい自然な応答が可能なチャットボットや自動応答システムを構築できます。日本の顧客の問い合わせ内容やニュアンスを正確に理解し、適切な情報提供や一次対応を行うことで、顧客満足度の向上とカスタマーサポート業務の効率化を実現します。
4. プログラミング支援
日本語での指示によるコード生成、日本語のコメントやドキュメントの自動生成、日本語のエラーメッセージの解説など、プログラミング開発における日本語でのコミュニケーションを円滑にします。特に、日本の開発現場で利用される日本語の変数名やコメント、ドキュメントスタイルに対応できる国産AIは、開発効率の向上に貢献します。
5. 研究開発・専門分野での活用
日本語で書かれた専門文献や研究論文の読解、要約、関連情報の検索を支援します。特定の専門分野(医療、法律、金融など)に特化した学習を行った国産AIは、その分野の専門用語や文脈を正確に理解し、研究者や専門家の情報収集・分析作業を効率化します。プライベート環境で運用できる国産AIは、機密性の高い研究データの取り扱いにも適しています。
6. コンテンツ生成・マーケティング
日本語のブログ記事、SNS投稿、広告コピー、メールマガジンなど、様々なマーケティングコンテンツのアイデア出しやドラフト作成を支援します。日本のターゲット層に響く、自然で魅力的な日本語表現を生成できる国産AIは、マーケティング活動の効率化と効果向上に貢献します。
これらの事例は、日本語特化・国産生成AIが日本の産業にもたらす可能性のほんの一例です。日本語の壁を低くし、国内での安心安全な運用を可能にする国産AIは、これまでAI活用が進みにくかった分野や業務においても、その導入を加速させる鍵となるでしょう。

国産生成AIの課題と今後の展望
日本語特化・国産生成AIは大きな可能性を秘めている一方で、いくつかの課題も存在します。
1. モデル性能のさらなる向上
海外のトップモデル(GPT-4o, Gemini 1.5 Pro, Claude 3 Opusなど)は、パラメータ数や学習データ量において依然として大規模であり、複雑な推論能力や幅広いタスクへの対応力で先行しています。国産AIがこれらの汎用AIに匹敵、あるいは凌駕するためには、モデルのアーキテクチャ開発、学習データの質と量の確保、計算リソースの確保など、さらなる技術開発と投資が必要です。
2. 学習データの質と量
日本語の高品質な学習データセットは、英語に比べて限られています。特に、特定の専門分野や業界に特化した高品質な日本語データの収集・整備は容易ではありません。学習データの質と量が、AIの性能を大きく左右するため、この点の強化が不可欠です。
3. 開発コストとリソース
大規模なLLMの開発には、膨大な計算リソース(GPUなど)と高度な専門知識を持つ人材が必要です。海外の巨大テック企業と比較すると、国内のリソースは限られているため、効率的な開発手法の確立や、産学連携によるリソース共有、人材育成が重要となります。
4. オープンソース化とコミュニティ形成
海外では、MetaのLlamaシリーズのように、高性能なモデルがオープンソースとして公開され、活発なコミュニティによって改良や応用が進められています。国内でもオープンソースの取り組みはありますが、さらなる活性化が必要です。オープンな開発体制は、技術の普及や新たなイノベーションの創出を加速させます。
5. 国際競争力とグローバル展開
国産AIが国内市場だけでなく、グローバル市場で競争力を持ち、海外に展開していくためには、多言語対応能力の強化や、国際的な標準への準拠なども視野に入れる必要があります。
今後の展望
これらの課題を克服しつつ、国産生成AIは今後も進化を続けるでしょう。特定の産業分野に特化した高性能モデルの開発、RAG技術などとの組み合わせによる実用性の向上、AIエージェント化による自律的なタスク実行能力の獲得などが期待されます。また、政府の支援や企業間の連携も進んでおり、日本のAI技術開発は加速していくと考えられます。
まとめ:あなたに最適なAIを見つけるために
生成AIの進化は止まりません。海外製の汎用AIは、その多機能性と圧倒的なパワーで私たちの可能性を広げてくれます。一方、日本語特化・国産生成AIは、日本語の壁を越え、国内での安心安全な運用を実現し、日本の産業に深く根差した活用を可能にします。
「国産生成AIはChatGPTを超えるか?」という問いに対する答えは、単純な優劣ではなく、「何をしたいか」「どのような環境で使いたいか」によって異なります。汎用的なタスクにはChatGPTやGemini、Claudeといった汎用AIが適しているかもしれません。しかし、日本語の微妙なニュアンスが重要、社内データを安全に扱いたい、日本の商習慣に合わせた応答が必要、といった場合には、日本語特化・国産AIが強力な選択肢となります。
まずは、無料プランやトライアルを活用して、様々なAIに触れてみることが重要です。そして、自社の業務や目的に照らし合わせ、それぞれのAIの得意分野を見極めてください。一つのAIにこだわる必要はありません。複数のAIを組み合わせる「ハイブリッド戦略」も有効です。
日本語特化・国産生成AIの発展は、日本のAI活用を次のステージへと引き上げる可能性を秘めています。これらのAIを賢く活用することで、あなたの仕事やビジネスは、きっともっと効率的で、創造的になるはずです。今後の国産AIの進化にも、ぜひ注目していきましょう。